This is a pretty cool result, especially for those of us who are building models for mobile/embedded systems!
As a quick summary, the problem the authors are trying to solve is this: suppose that you have a convolutional neural network that performs some task and uses X amount of computation. Now you have access to, say, 2X computation --- how should you change your model to best use the extra computation?
Generally people have taken advantage of the extra computation by widening the layers, using more layers (but of the same width), or increasing the resolution of the image. In this paper the authors show that if you do any of these individually, the performance of the NN saturates, but if you do all of them at the same time, you can achieve much higher accuracy.
Specifically what they do is conduct a small grid search in the vicinity of the original NN and vary the width, depth, and resolution to figure out the best combination. Then they just use those scalings to scale up to the required compute. This seems to work well across a variety of different tasks.
The main gripe I had with the paper was that they didn't do another grid search around the scaled up NN to verify that that the scaling actually held. In practice it seems to produce pretty efficient NNs, but maybe the scaling doesn't extrapolate perfectly and you can get an even better NN by applying some correction.
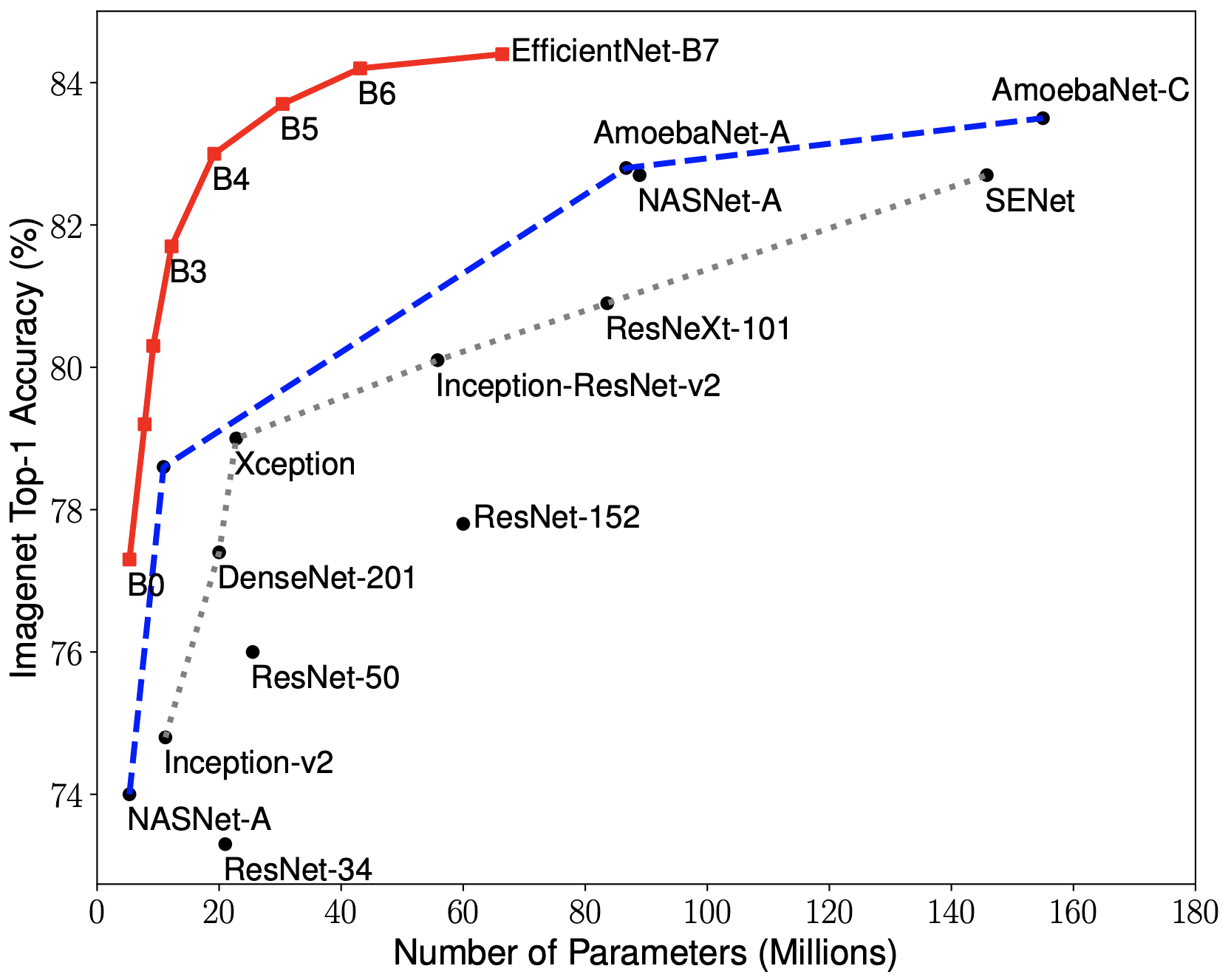
The results in this paper are quite astounding. Specifically the improvement in efficiency and accuracy of their EfficientNet architecture over state-of-the-art feature extraction backbones is simply amazing (see Fig 1. from the paper - https://raw.githubusercontent.com/tensorflow/tpu/master/mode...). AFAICT, this is a huge leap in improvement, and what's fascinating is how fundamentally simple the entire premise of this paper and the type of experiments performed was.
Pretty much everyone will want to switch their feature extractors to some flavor of a pre-trained EfficientNet for any image classification / object detection type application going forward. I'm also excited to see the improvements in speed and accuracy that this can enable for mobile/embedded systems.
You could think of this as being hyperparameter tuning, but that would be simplistic. Previous approaches have tried to hold most of architecture constant and then scientifically report the results of tweaking a particular variable for verifiable results. Quoc has been working with evolutionary approaches to performing these sort of experiments with large clusters. Most of the results so far have been technically superior, but at the cost of complexity/understandability. Here though, is the logical conclusion of this approach done at scale: using evolutionary approaches to explore a large swath of architecture space, finding an entirely new category of convolutional networks, then working backwards to a formal/clean architecture and paper.
{kind=link}
As a quick summary, the problem the authors are trying to solve is this: suppose that you have a convolutional neural network that performs some task and uses X amount of computation. Now you have access to, say, 2X computation --- how should you change your model to best use the extra computation?
Generally people have taken advantage of the extra computation by widening the layers, using more layers (but of the same width), or increasing the resolution of the image. In this paper the authors show that if you do any of these individually, the performance of the NN saturates, but if you do all of them at the same time, you can achieve much higher accuracy.
Specifically what they do is conduct a small grid search in the vicinity of the original NN and vary the width, depth, and resolution to figure out the best combination. Then they just use those scalings to scale up to the required compute. This seems to work well across a variety of different tasks.
The main gripe I had with the paper was that they didn't do another grid search around the scaled up NN to verify that that the scaling actually held. In practice it seems to produce pretty efficient NNs, but maybe the scaling doesn't extrapolate perfectly and you can get an even better NN by applying some correction.